本文共 1028 字,大约阅读时间需要 3 分钟。
1. 什么是End-to-End 学习
要知道什么是End-to-End学习首先要知道传统的非End-to-End学习是什么。以语义分类(判断评论为正面评论还是负面评论)为例,非End-to-End的学习需要对语音识别之前要经过两步处理:解析器(Parser) 注释文本和情感分类器(Sentiment Classifier)预测文本。
解析器是对文本进行标注,比如形容词(好,坏,糟糕等),情感分类器再来预测文本是正面的还是负面的,整个过程如图:

End-to-End 学习不需要这些步骤,像黑盒子一样一步到位解决问题。神经网络算法就是一个被广泛应用的End-to-End学习的算法。End-to-End 算法尤其适用于数据量巨大的机器学习任务中。

2. 更多End-to-End 的例子
在语音识别领域,非End-to-End 的学习大致经历:计算特征解析得到人工设计的频谱特征,音素(Phonemes)识别器识别语音中的“音素”和最终识别三个步骤:

然而End-to-End 也只需要一步就搞定了

3. End-to-End 学习的优缺点
非End-to-End的学习算法中,需要人类做大量的前期准备工作,比如在上述语音识别的例子中,"音素"是语言学家发明的,在处理过程虽然提高了效率但是无疑会丢失语音中的其他信息。但是这种算法需要的数据量比较小。
End-to-End学习算法虽然不需要太多的人工干预,但是需要大量标记的数据,并不是在所有领域都是最好的选择。
4.非End-to-End 学习算法中pipline(管道)的选择
正如上文提到的,End-to-End的学习方法并不是在所有的领域都是最好的选择。最重要的是到底有没有足够可靠的数据。以自动驾驶为例,通过摄像头识别人和车辆,然后规划驾驶路径。如果用End-to-End的方法,需要积累海量量标记好的数据,各种路况不同的路径规划,非常困难。
然而,如果使用非End-to-End的方法,比如下图,先识别车和人,再进行路径规划
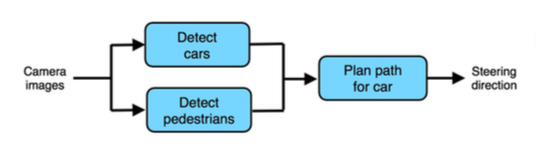
人和车的被标记好的数据很容易找到,完成这一步,再进行路径规划,这样训练起来就容易很多了。而这样设计算法的步骤就是pipline.
再举一个识别图片中猫的品种的例子,我们可以这样设计Pipline: 第一步先识别图片中是否有猫,第二步再识别猫是不是这个品种:

转载地址:http://stzjx.baihongyu.com/